6.5 ווב סקרייפינג הרצאה
הקדמה¶
- בשיעור הזה נגע קצת בנושא מאוד רחב שנקרא web scraping, אם אתם מוצאים את הנושא כמעניין אתם מוזמנים לחקור עליו עוד :)
אתרים על רגל אחת¶
- יש המון אתרים באינטרנט, לכל אתר יש בדרך כלל מספר עמודים שונים
- לכל עמוד באינטרנט יש קישור (URL) שנראה כך: https://docs.python.org/3/
- כמו שלתוכנות יש קוד, גם לעמודי אינטרנט יש קוד שבונה את העמוד, זה נקרא html - ראשי תבות של hypertext markup languege
- כאשר אנחנו נגשים לעמוד באינרנט, הדפדפן שלנו מקבל html מהאתר, ויודע להציג לנו אותו.
- אפשר לחשוב על html כשפה שבונה את העמוד
ווב-סקרייפינג - web scraping¶
- ווב-סקרייפינג זה היכולת שלנו לחלץ מעמודי אינטרנט - למשל לחלץ מהhtml שלהם מידע שמעניין אותנו
- ווב-סקרייפינג משמש אותנו בדרך כלל כשאנחנו רוצים לבנות מאגר של מידע, היכולת נותנת לנו לחלץ מידע שאנחנו רוצים מאתרים, תהליך זה נקרא חציבת מידע או באנגלית data -mining
שליפת הhtml של אתרים¶
- פתחו את https://www.google.com
- לחצו על f12
- זה נקרא הdeveloper tools של הדפדפן או בקיצור devtools, הוא מאפשר לנו לראות את הhtml של אתרים, לראות את הקוד של האתר, ועוד המון מידע על האתר
מבנה HTML¶
אז איך HTML נראה? נפתח את האתר http://books.toscrape.com ונפתח את הdevtools, ונבחר עם הסממן של הdevtools למשל את אחת התמונות באתר:
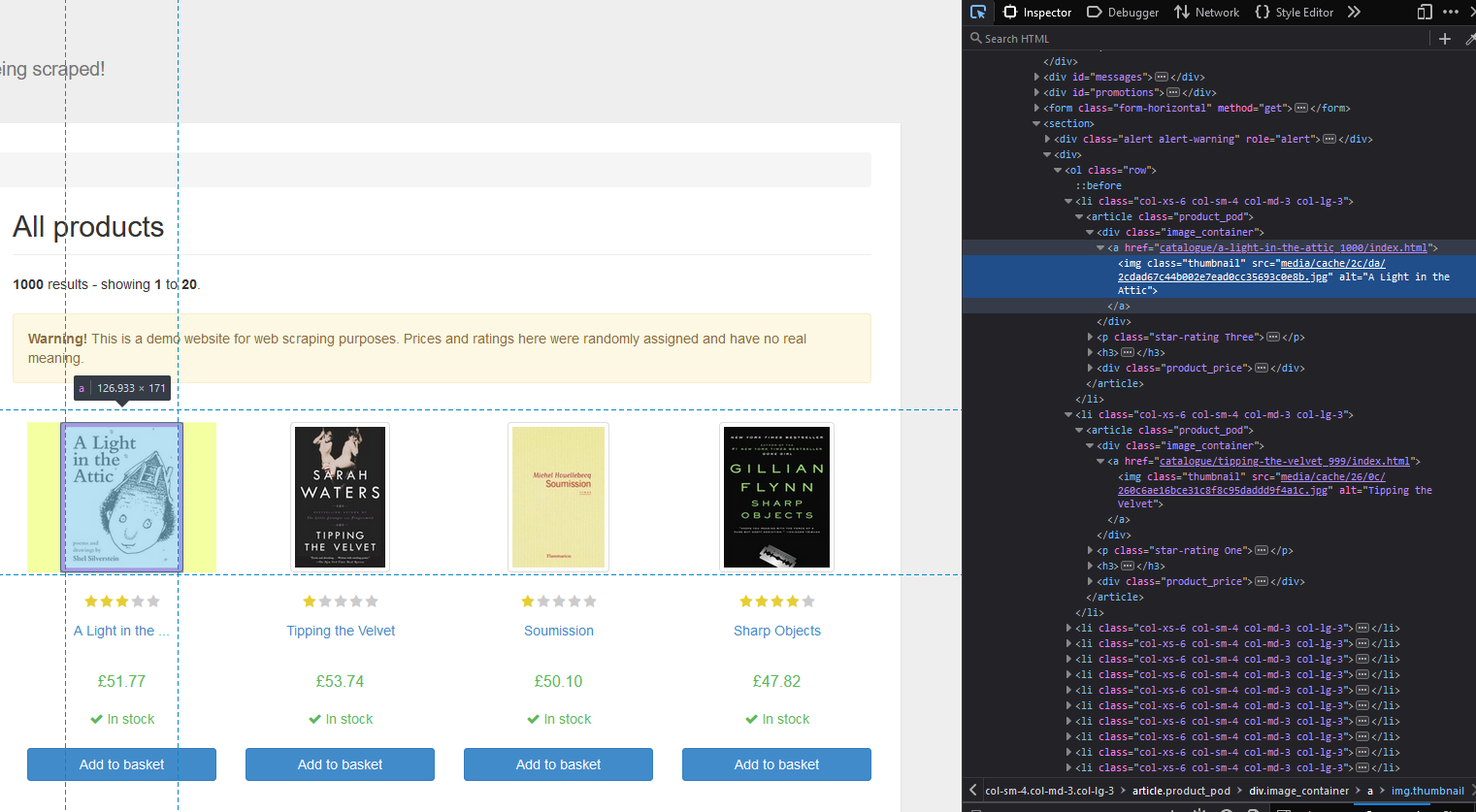
- אפשר לראות את הhtml של העמוד, ואפילו את השורת html שמראה לנו את התמונה שבחרנו:
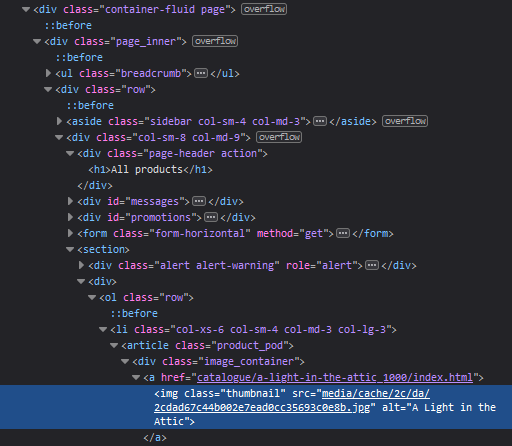
- כל עמוד html בנוי "בתגיות", תגית היא למשל:
- תגית קישור - <a>
- תגית תמונה - <img>
- תגית כותרת - <h>
- תגית <p>
מודול urllib¶
- בשימוש המודול המובנה
urllibאנחנו יכולים לשלוף את הhtml של אתרים.
- המשתנה html_content יכיל את כל הhtml של העמוד http://books.toscrape.com/
מודול BeautifulSoup¶
- עם שימוש במודול החיצוני
BeautifulSoupאנחנו יכולים לחלץ בפשטות מHTML-ים את המידע הספציפי שאנחנו רוצים - הריצו
pip install bs4
from bs4 import BeautifulSoup # Assuming 'html_content' is the HTML content obtained using urllib soup = BeautifulSoup(html_content, 'html.parser') # Extracting title title = soup.title print("Title:", title.text) # Extracting all books paragraphs = soup.find_all('h3') for paragraph in paragraphs: print("Paragraph:", paragraph.text) # Extracting all links links = soup.find_all('a') for link in links: print("Link:", link.get('href')) - בקוד הבא השתמשנו בפונקציה
soup.findallכדי לחלץ את כל התגיות בhtml מסוג מסויים,- הפונקציה
soup.find_all('h3')תחלץ את כל התגיות מסוגh3שמקרה שלנו זה השמות של הספרים באתר - הפונקציה
soup.find_all('a')תחלף.את כל התגיות מסוגaשבמקרה שלנו זה הקישורים לספרים
- הפונקציה
מחלץ המשפטים¶
- נכתוב תוכנה שמחלצת משפטים מהאתר http://quotes.toscrape.com
from urllib.request import urlopen from bs4 import BeautifulSoup url = "http://quotes.toscrape.com" response = urlopen(url) html_content = response.read() # Parse the HTML content soup = BeautifulSoup(html_content, 'html.parser') # Extract quotes and authors quotes = soup.find_all('span', class_='text') authors = soup.find_all('small', class_='author') for quote, author in zip(quotes, authors): print("Quote:", quote.text) print("Author:", author.text) print() - השתמשנו שוב ב
findallכדי לחלץ תגיות, רק שהפעם נתו גם פרמטר שיש לתגיותclassשמזהה רק תגיות ספציפיות:

- אנחנו רוצים את כל התגיות שהם מסוג span והפרמטר class שלהם שווה לtext אז הקריאה ל
findallתהיה כך:soup.find_all('span', class_='text')
ווב-סקרייפינג דינמי¶
- תראו את האתר חיפוש משרות הבא: https://www.freelancer.com/jobs/
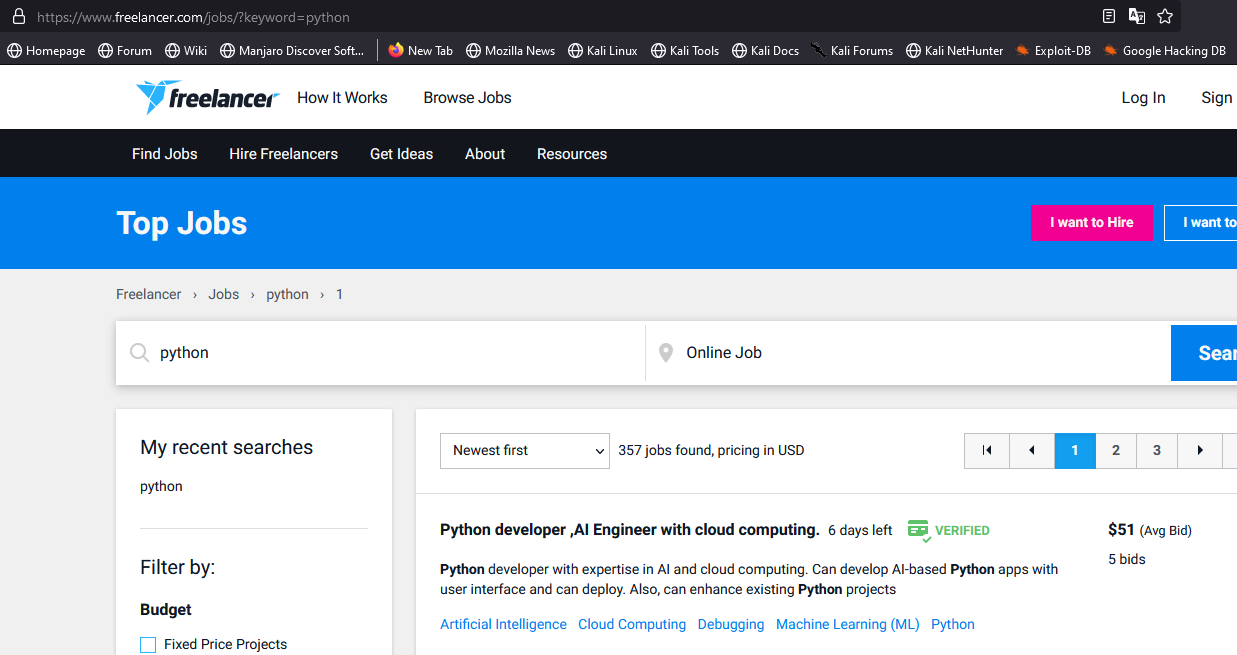
- נראה שאם אנחנו מחפשים איזשהי משרה באתר, הוא פותח לנו עמוד שהקישור שלו נראה כך
https://www.freelancer.com/jobs/?keyword=python
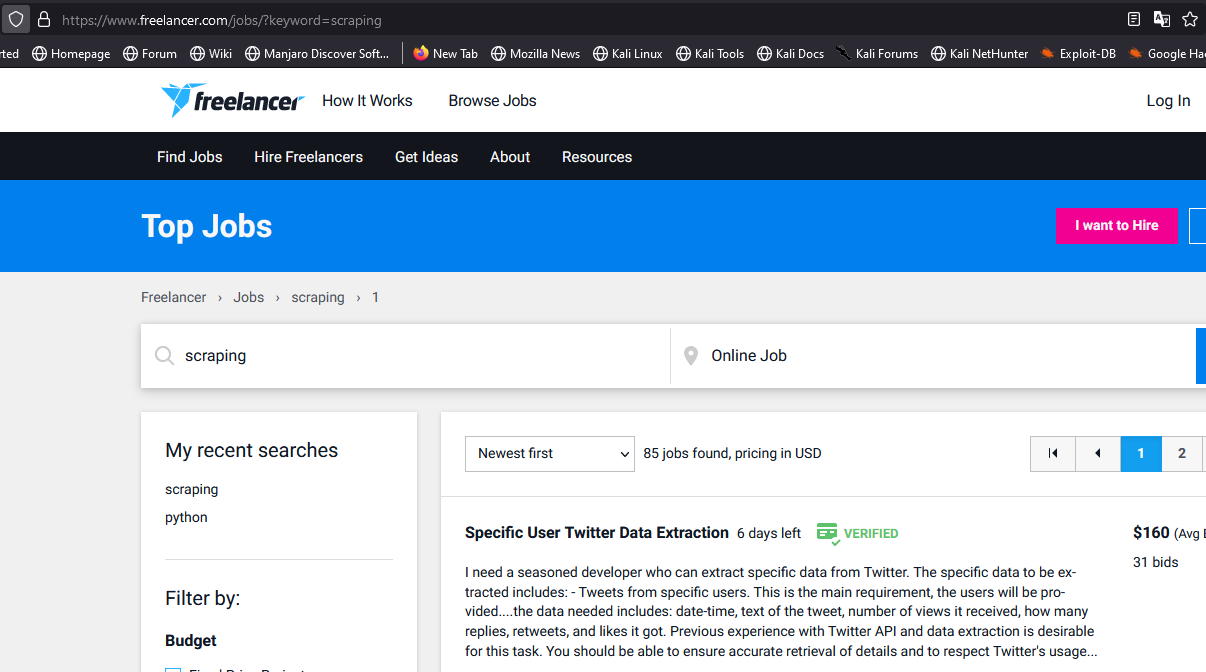
- זה אומר שהקישור הבא:
https://www.freelancer.com/jobs/?keyword=scrapingיביא לנו משרות שקשורת לscraping - כל פעם שאנחנו מקלידים שם שונה של משרה אנחנו מקבלים עמוד אחר, אנחנו יכולים לנצל את העובדה שאנחנו יכולים להעביר לו בכל פעם בקישור שם של משרה כדי לעשות סקייפינג דינמי.
from urllib.request import urlopen from bs4 import BeautifulSoup def search_for_job(job: str): url = f"https://www.freelancer.com/jobs/?keyword={job}" response = urlopen(url) html_content = response.read() # Parse the HTML content soup = BeautifulSoup(html_content, 'html.parser') heading = soup.find_all('a', class_='JobSearchCard-primary-heading-link') descriptions = soup.find_all('p', class_='JobSearchCard-primary-description') price = soup.find_all('div', class_='JobSearchCard-primary-price') for head, description, price in zip(heading, descriptions, price): print(f"{head.text}: - {price.text} - {description.text}") while True: job = input("Enter a job to search for: ") search_for_job(job) - כאן עשינו מניפולציה על הפרמטר שאנחנו מעבירים בקישור כדי לגנוב את כל המשרות מהאתר.
זכרו¶
- לפני שאתם עושים ווב-סקריפינג על אתר בדקו שיש להם אפשרות לעשות זאת ממנהל האתר, גניבה של תוכן עם קפירייט יכול להיחשב לא חוקי ולא אתי.